Overview
Architected a multi-agent poker benchmark evaluating 17 frontier LLMs across 20,000+ hands of 10-seat No-Limit Texas Hold'em. The benchmark is public and live at vals.ai/benchmarks/poker_agent. The headline finding: benchmark scores don't predict strategic reasoning. Models that dominate standardized tests underperformed against models built for adversarial decision-making. Crushing benchmarks is not the same as making good decisions under pressure.
What I built
On a 4-person Graphite Digital team partnered with Vals AI, I owned the context management architecture, the JSON logging system, the analysis scripts, the case studies, the technical documentation, and the execution of 20,000 hands across 10 providers (OpenAI, Anthropic, Google, Together, Mistral, AI21 Labs, Grok, Fireworks, DeepSeek, and more).
- Tiered context. The current hand carries full reasoning traces. The previous 25 hands carry only board states and resulting actions. This preserves the behavioral signal a model needs to read opponents (for example, "Anthropic tends to fold") while keeping token use sane. Full reasoning for every hand would have blown context past 100K tokens.
- Hierarchical JSON logging. Separates persistent seat identity from per-hand positional role. Each action logs timestep, player, seat, action, chip change, stack, board, and full model metadata (provider, latency, token counts, reasoning). Saves after every hand, not every game, so overnight runs survive interruptions and games run in parallel.
- Deterministic seeding. 10 seeds times 10 seatings gives roughly 100 independent views of each matchup, cutting standard error while preserving realistic variance. Seatings randomize position to neutralize the positional bias baked into No-Limit Hold'em.
- Provider-specific handling. OpenAI and Anthropic use conversation history. The rest receive complete context in each prompt.
- Stack: Python, PokerKit (game engine), TrueSkill rating system, JSON logging, tmux for persistent runs, REST APIs across 10 providers.
What the benchmark found
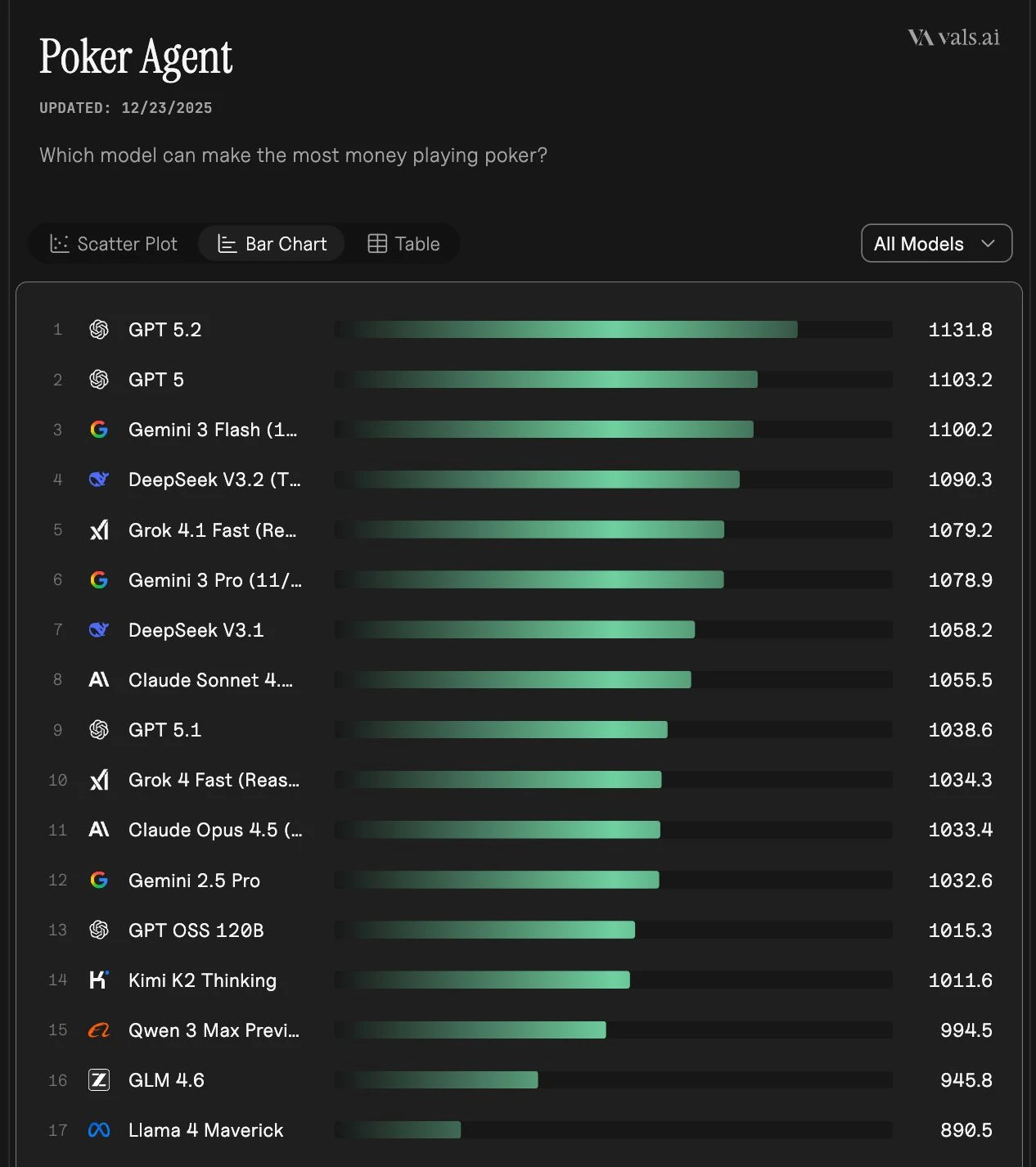
- GPT-5.2 ranked first (1131.8 TrueSkill), GPT-5 second, Gemini 3 Flash third within roughly 3 TrueSkill points at about one tenth the cost.
- Cost did not buy proportional skill. GPT-5.2 is roughly 10x the cost and 20x the latency of models a few points behind it.
- Open source held up. DeepSeek V3.2 (Thinking) hit 1090.3 TrueSkill at $0.0135 per hand.
- Play styles varied widely. Grok 4.1 Fast (Reasoning) was the most aggressive (57.2% aggressive post-flop actions); the Gemini line played far more conservatively.
- Identical cards, different fates. One pocket Aces case study produced a 539-chip outcome spread across models holding the same starting hand.
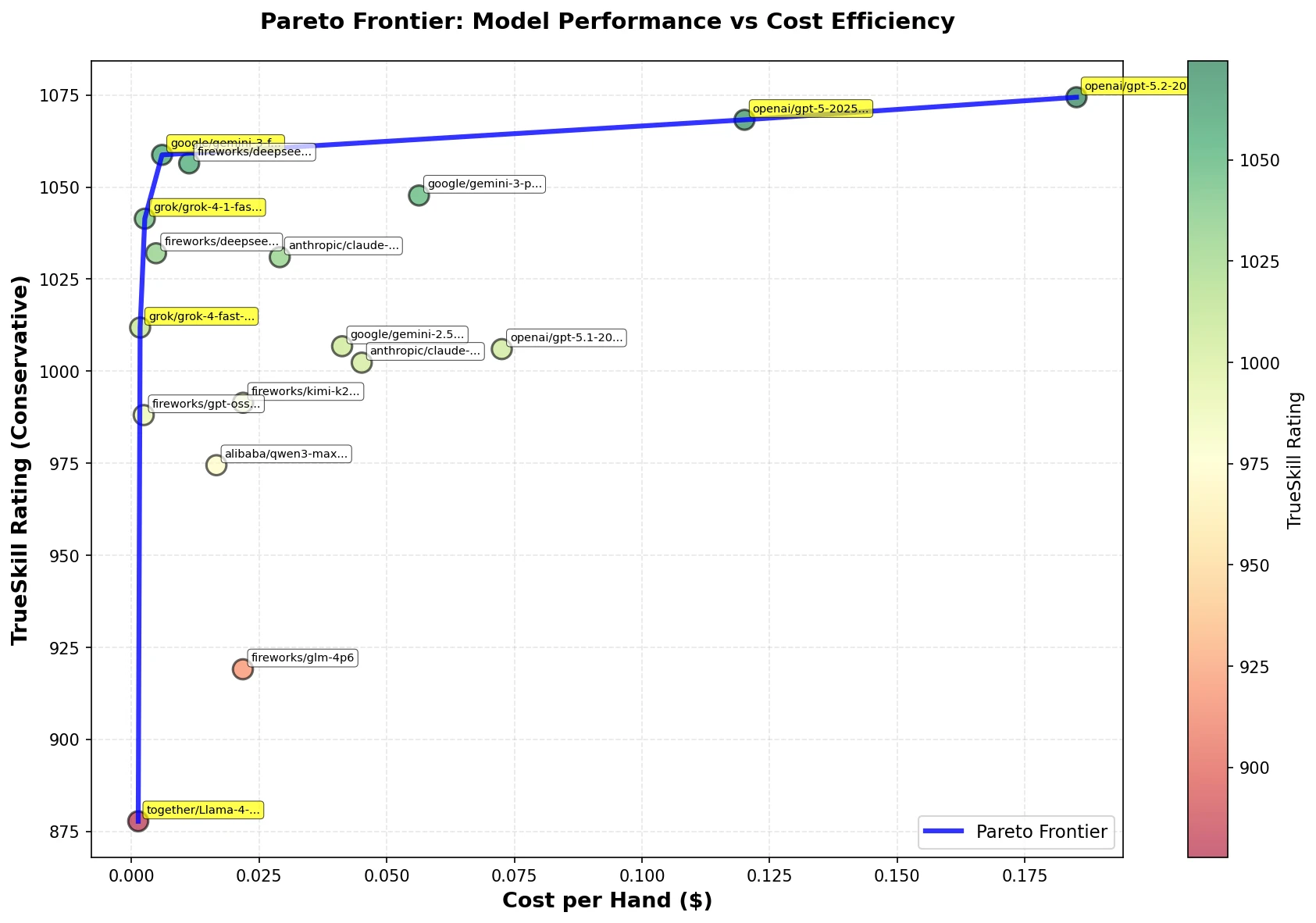
Performance versus cost per hand. The strongest model sits far to the right, well past the point of diminishing returns.
The hardest bug
Eliminated players (zero chips) were re-entering games and receiving chips from nowhere. I caught it by writing anomaly detection scripts that flagged chip-count patterns where players rose from zero without a buy-in. The root cause was model sampling drawing from the same random seed and corrupting PokerKit's downstream state. The fix was a redesign of seed management for deterministic, reproducible game states across the full tournament. NumPy seeding intuition did not transfer here. The interaction between LLM sampling and game-engine randomness needed every stochastic element isolated and explicitly seeded at each decision point.
If I did it again, I would build a custom poker engine from day one instead of adapting PokerKit. Most of the worst bugs traced back to PokerKit assumptions that do not hold when the players are LLM agents.
The interactive report
Full leaderboard, methodology, and case studies, live at vals.ai/benchmarks/poker_agent.